

Как создать собственную нейронную сеть с нуля на языке Python
Как создать собственную нейронную сеть с нуля на языке Python
Джеймс Лой, Технологический университет штата Джорджия. Руководство для новичков, после которого вы сможете создать собственную нейронную сеть на Python.
Мотивация: ориентируясь на личный опыт в изучении глубокого обучения, я решил создать нейронную сеть с нуля без сложной учебной библиотеки, такой как, например, TensorFlow. Я считаю, что для начинающего Data Scientist-а важно понимание внутренней структуры нейронной сети.
Эта статья содержит то, что я усвоил, и, надеюсь, она будет полезна и для вас! Другие полезные статьи по теме:
Изучаем нейронные сети за четыре шага

В этот раз я решил изучить нейронные сети. Базовые навыки в этом вопросе я смог получить за лето и осень 2015 года. Под базовыми навыками я имею в виду, что могу сам создать простую нейронную сеть с нуля. Примеры можете найти в моих репозиториях на GitHub. В этой статье я дам несколько разъяснений и поделюсь ресурсами, которые могут пригодиться вам для изучения.
Шаг 1. Нейроны и метод прямого распространения
Так что же такое «нейронная сеть»? Давайте подождём с этим и сперва разберёмся с одним нейроном.
Нейрон похож на функцию: он принимает на вход несколько значений и возвращает одно.
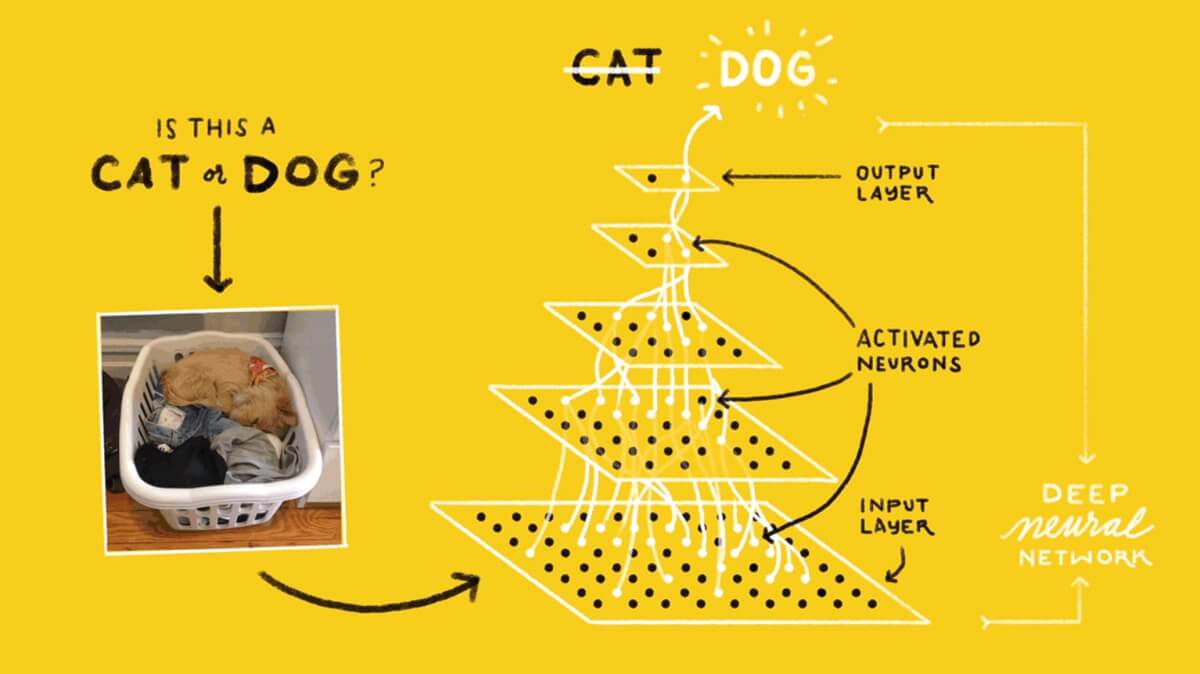
Круг ниже обозначает искусственный нейрон. Он получает 5 и возвращает 1. Ввод — это сумма трёх соединённых с нейроном синапсов (три стрелки слева).
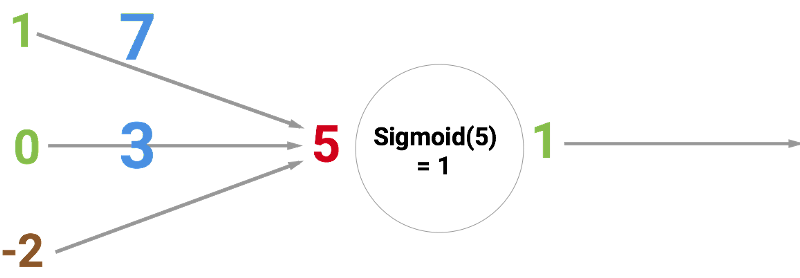
В левой части картинки мы видим 2 входных значения (зелёного цвета) и смещение (выделено коричневым цветом).
«Ситиконсалт», удалённо, 200 000 ₽
Входные данные могут быть численными представлениями двух разных свойств. Например, при создании спам-фильтра они могли бы означать наличие более чем одного слова, написанного ЗАГЛАВНЫМИ БУКВАМИ, и наличие слова «виагра».
Входные значения умножаются на свои так называемые «веса», 7 и 3 (выделено синим).
Теперь мы складываем полученные значения со смещением и получаем число, в нашем случае 5 (выделено красным). Это — ввод нашего искусственного нейрона.

Потом нейрон производит какое-то вычисление и выдает выходное значение. Мы получили 1, т.к. округлённое значение сигмоиды в точке 5 равно 1 (более подробно об этой функции поговорим позже).
Если бы это был спам-фильтр, факт вывода 1 означал бы то, что текст был помечен нейроном как спам.

Иллюстрация нейронной сети с Википедии.
Если вы объедините эти нейроны, то получите прямо распространяющуюся нейронную сеть — процесс идёт от ввода к выводу, через нейроны, соединённые синапсами, как на картинке слева.
Я очень рекомендую посмотреть серию видео от Welch Labs для улучшения понимания процесса.
Шаг 2. Сигмоида
После того, как вы посмотрели уроки от Welch Labs, хорошей идеей было бы ознакомиться с четвертой неделей курса по машинному обучению от Coursera, посвящённой нейронным сетям — она поможет разобраться в принципах их работы. Курс сильно углубляется в математику и основан на Octave, а я предпочитаю Python. Из-за этого я пропустил упражнения и почерпнул все необходимые знания из видео.

Сигмоида просто-напросто отображает ваше значение (по горизонтальной оси) на отрезок от 0 до 1.
Первоочередной задачей для меня стало изучение сигмоиды, так как она фигурировала во многих аспектах нейронных сетей. Что-то о ней я уже знал из третьей недели вышеупомянутого курса, поэтому я пересмотрел видео оттуда.
Но на одних видео далеко не уедешь. Для полного понимания я решил закодить её самостоятельно. Поэтому я начал писать реализацию алгоритма логистической регрессии (который использует сигмоиду).
Это заняло целый день, и вряд ли результат получился удовлетворительным. Но это неважно, ведь я разобрался, как всё работает. Код можно увидеть здесь.
Вам необязательно делать это самим, поскольку тут требуются специальные знания — главное, чтобы вы поняли, как устроена сигмоида.
Шаг 3. Метод обратного распространения ошибки
Понять принцип работы нейронной сети от ввода до вывода не так уж и сложно. Гораздо сложнее понять, как нейронная сеть обучается на наборах данных. Использованный мной принцип называется методом обратного распространения ошибки.
Вкратце: вы оцениваете, насколько сеть ошиблась, и изменяете вес входных значений (синие числа на первой картинке).
Процесс идёт от конца к началу, так как мы начинаем с конца сети (смотрим, насколько отклоняется от истины догадка сети) и двигаемся назад, изменяя по пути веса, пока не дойдём до ввода. Для вычисления всего этого вручную потребуются знания матанализа. Khan Academy предоставляет хорошие курсы по матанализу, но я изучал его в университете. Также можно не заморачиваться и воспользоваться библиотеками, которые посчитают весь матан за вас.

Скриншот из руководства Мэтта Мазура по методу обратного распространения ошибки.
Вот три источника, которые помогли мне разобраться в этом методе:
В процессе прочтения первых двух статей вам обязательно нужно кодить самим, это поможет вам в дальнейшем. Да и вообще, в нейронных сетях нельзя как следует разобраться, если пренебречь практикой. Третья статья тоже классная, но это скорее энциклопедия, поскольку она размером с целую книгу. Она содержит подробные объяснения всех важных принципов работы нейронных сетей. Эти статьи также помогут вам изучить такие понятия, как функция стоимости и градиентный спуск.
Шаг 4. Создание своей нейронной сети
При прочтении различных статей и руководств вы так или иначе будете писать маленькие нейронные сети. Рекомендую именно так и делать, поскольку это — очень эффективный метод обучения.
Ещё одной полезной статьёй оказалась A Neural Network in 11 lines of Python от IAmTrask. В ней содержится удивительное количество знаний, сжатых до 11 строк кода.

Скриншот руководства от IAmTrask
После прочтения этой статьи вам следует написать реализацию всех примеров самостоятельно. Это поможет вам закрыть дыры в знаниях, а когда у вас получится, вы почувствуете, будто обрели суперсилу.
Поскольку в примерах частенько встречаются реализации, использующие векторные вычисления, я рекомендую пройти курс по линейной алгебре от Coursera.
После этого можно ознакомиться с руководством Wild ML от Denny Britz, в котором разбираются нейронные сети посложнее.

Скриншот из руководства WildML
Теперь вы можете попробовать написать свою собственную нейронную сеть или поэкспериментировать с уже написанными. Очень забавно найти интересующий вас набор данных и проверить различные предположения при помощи ваших сетей.
Для поиска хороших наборов данных можете посетить мой сайт Datasets.co и выбрать там подходящий.
Так или иначе, теперь вам лучше начать свои эксперименты, чем слушать мои советы. Лично я сейчас изучаю Python-библиотеки для программирования нейронных сетей, такие как Theano, Lasagne и nolearn.
Какие задачи глубокое обучение решает сегодня?
С появлением экономически эффективных вычислительных мощностей и накопителей данных глубокое обучение проникло во все цифровые аспекты нашей повседневной жизни. Вот несколько примеров цифровых продуктов из обычной жизни, в основе которых лежит глубокое обучение:
- популярные виртуальные помощники Siri/Alexa/Google Assistant;
- предложение отметить друга на только что загруженной фотографии в Facebook;
- автономное вождение в автомобилях Tesla;
- фильтр с кошачьими мордами в Snapchat;
- рекомендации в Amazon и Netflix;
- недавно выпущенные, но получившие вирусную популярность приложения для обработки фото — FaceApp и Prisma.
Возможно, вы уже пользовались приложениями с применением глубокого обучения и просто не знали об этом.
Глубокое обучение проникло буквально во все отрасли. К примеру, в здравоохранении с его помощью диагностируют онкологию и диабет, в авиации — оптимизируют парки воздушных судов, в нефтегазовой индустрии— проводят профилактическое техобслуживание оборудования, в банковской и финансовой сферах — отслеживают мошеннические действия, в розничной торговле и телекоммуникациях — прогнозируют отток клиентов и т. д. Эндрю Ын верно назвал ИИ новым электричеством: подобно тому, как электричество в своё время изменило мир, ИИ также изменит практически всё в ближайшем будущем.
Нейронные сети с нуля. Обзор курсов и статей на русском языке, бесплатно и без регистрации
На Хабре периодически появляются обзоры курсов по машинному обучению. Но такие статьи чаще добавляют в закладки, чем проходят сами курсы. Причины для этого разные: курсы на английском языке, требуют уверенного знания матана или специфичных фреймворков (либо наоборот не описаны начальные знания, необходимые для прохождения курса), находятся на других сайтах и требуют регистрации, имеют расписание, домашнюю работу и тяжело сочетаются с трудовыми буднями. Всё это мешает уже сейчас с нуля начать погружаться в мир машинного обучения со своей собственной скоростью, ровно до того уровня, который интересен и пропускать при этом неинтересные разделы.
В этом обзоре в основном присутствуют только ссылки на статьи на хабре, а ссылки на другие ресурсы в качестве дополнения (информация на них на русском языке и не нужно регистрироваться). Все рекомендованные мною статьи и материалы я прочитал лично. Я попробовал каждый видеокурс, чтобы выбрать что понравится мне и помочь с выбором остальным. Большинство статей мною были прочитаны ранее, но есть и те на которые я наткнулся во время написания этого обзора.
Обзор состоит из нескольких разделов, чтобы каждый мог выбрать уровень с которого можно начать.
Для крупных разделов и видео-курсов указаны приблизительные временные затраты, необходимые знания, ожидаемые результаты и задания для самопроверки.
Большинство статей не было написано в рамках единого курса, поэтому информация может дублироваться. Если вы видите, что знаете какую-то часть статьи, то можете её смело пропустить, если вы не разорались с этой информацией в предыдущей статье, то у вас есть шанс прочитать тоже самое, но другими словами, что должно помочь усвоению материала.
Вводные статьи
Требуемый уровень: школьное образование, знание русского языка.
Требуемое время: несколько часов.
Казалось бы, что стоит начать изучение со статьи Искусственная нейронная сеть на википедии, но я не рекомендую. Наискучнейшее описание отбивает всё желание изучать нейронные сети.
Расширяем горизонты
Требуемый уровень: базовое понимание работы нейронных сетей.
Требуемое время: несколько часов.
Перечислите основные:
- типы задач, которые решают нейронные сети
- типы архитектур нейронных сетей
- функции активации
- типы нейронов / слоёв
Углубляем знания
Требуемый уровень: понимание работы нейронных сетей, знание базовых архитектур.
Требуемое время: несколько десятков часов.
Чтобы определиться самому и помочь с выбором остальным хабровчанам, я построил график падения интереса к курсу на основе падения количества просмотров каждого следующего ролика. Выводы неутешительные — мало кто доходит до конца. Самый большой процент дошедших до конца — у курса от АФТИ НГУ.
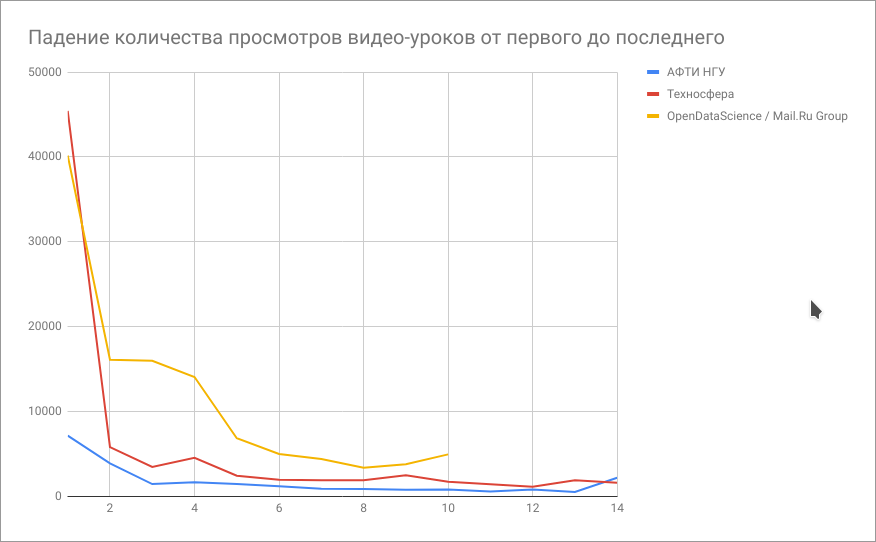
(График падения количества просмотров составлялся пару месяцев назад и текущая картина может немного отличаться).
Примеры применения на практике
Сюда вошли в основном только те статьи, после которых прочитавшие их люди смогут сами воспроизвести описанные результаты (есть ссылки на исходники или онлайн сервисы)
Другие материалы
Статьи и курсы, которые не вошли в мой обзор, но возможно вам понравятся.
Другие статьи-обзоры на хабре по изучению машинного обучения
Прочтение этих статей и подтолкнуло меня написать свою собственную, в которой были бы материалы только на русском языке, без регистрации и требования 5 лет матана.
Надеюсь, что у моей статьи будет меньше комментариев вида:
«Закинул в закладки. Смотреть я их, конечно, не буду.»
Прошу всех заинтересованных лиц ответить на опросы после статьи, ну и подписывайтесь, чтобы не пропустить мои следующие статьи, ставьте лайки, чтобы мотивировать меня на их написание и пишите в комментариях вопросы (опечатки лучше в личку).
Традиционное предупреждение: я не отвечаю на сообщения в личку/соцсетях/телеграмме и т.д. Если у вас есть вопрос, то задавайте его в комментариях.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Программа курса Введение в нейронные сети на Python
- Простейшие нейронные сети
- Теоретическая часть: основные понятия; классификация задач, решаемых с помощью методов машинного обучения; виды данных, понятие датасета; полносвязные нейронные сети.
- Практическая часть: первичный анализ датасета, предобработка данных, построение полносвязной нейронной сети.
- Математические основы нейронных сетей
- Теоретическая часть: метрики качества работы нейронной сети, градиентный спуск, алгоритм обратного распространения ошибки, эффект переобучения.
- Практическая часть: тонкая настройка нейронной сети на примере задачи классификации изображений.
- Свёрточные нейронные сети
- Теоретическая часть: параметры сверточных нейронных сетей, предобученные нейронные сети.
- Практическая часть: использование предобученных нейронных сетей на примере задачи классификации изображений.
- Решение кейса: “Классификация изображений”
- Теоретическая часть: построение набора данных, фильтрация и предобработка данных.
- Практическая часть: решение кейса.
- Использование нейронных сетей вproduction
- Теоретическая часть: сериализация/десериализация объектов в Python, фреймворк Flask.
- Практическая часть: создание веб-сервиса на фреймворке Flask.
Нейронные сети простыми словами
Избегая сложных формулировок и нагромождений терминов, нейронную сеть проще всего описать как устройство, функционирующее по принципу головного мозга человека. Нейронные сети могут быть самых разных видов (сверточные, рекуррентные, прямого распространения и д.р.), отличаться по типу поставленной задачи (анализ, прогнозирование, распознавание образов и т.д.) и по своей структуре, однако в любом случае это некая математическая модель, представленная в виде программного и аппаратного обеспечения и имеющая целью обучиться делать выводы из обновляемых данных подобно человеку, принимающему то или иное жизненное решение.

Это своеобразный счетчик, который увеличивается каждый раз, когда нейронная сеть проходит один тренировочный сет. Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.
При инициализации нейронной сети эта величина устанавливается в 0 и имеет потолок, задаваемый вручную. Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат. Эпоха увеличивается каждый раз, когда мы проходим весь набор тренировочных сетов, в нашем случае, 4 сетов или 4 итераций.

Важно не путать итерацию с эпохой и понимать последовательность их инкремента. Сначала n
раз увеличивается итерация, а потом уже эпоха и никак не наоборот. Другими словами, нельзя сначала тренировать нейросеть только на одном сете, потом на другом и тд. Нужно тренировать каждый сет один раз за эпоху. Так, вы сможете избежать ошибок в вычислениях.
Создание рекуррентной нейронной сети на примере
Представим, что у нас есть нейронная сеть, которая работает по принципу «многое ко многим«. Входные данные — x , х 1, … x n, а результаты вывода — y , y 1, … y n. Данные x i и y i являются векторами и могут быть произвольных размеров.
Рекуррентные нейронные сети RNN работают путем итерированного обновления скрытого состояния h , которое является вектором, что также может иметь произвольный размер. Стоит учитывать, что на любом заданном этапе t :
- Следующее скрытое состояние h t подсчитывается при помощи предыдущего h t — 1 и следующим вводом x t;
- Следующий вывод y t подсчитывается при помощи h t.
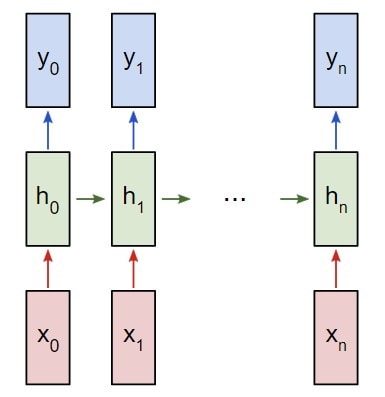 Рекуррентная нейронная сеть RNN многие ко многим
Рекуррентная нейронная сеть RNN многие ко многим
Вот что делает нейронную сеть рекуррентной: на каждом шаге она использует один и тот же вес. Говоря точнее, типичная классическая рекуррентная нейронная сеть использует только три набора параметров веса для выполнения требуемых подсчетов:
- W xh используется для всех связок x t → h t
- W hh используется для всех связок h t-1 → h t
- W hy используется для всех связок h t → y t
Для рекуррентной нейронной сети мы также используем два смещения:
- b h добавляется при подсчете h t
- b y добавляется при подсчете y t
Вес будет представлен как матрица, а смещение как вектор. В данном случае рекуррентная нейронная сеть состоит их трех параметров веса и двух смещений.
Следующие уравнения являются компактным представлением всего вышесказанного:
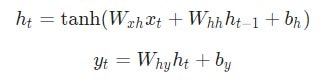 Разбор уравнений лучше не пропускать. Остановитесь на минутку и изучите их внимательно. Помните, что вес — это матрица, а другие переменные являются векторами.
Разбор уравнений лучше не пропускать. Остановитесь на минутку и изучите их внимательно. Помните, что вес — это матрица, а другие переменные являются векторами.
Говоря о весе, мы используем матричное умножение, после чего векторы вносятся в конечный результат. Затем применяется гиперболическая функция в качестве функции активации первого уравнения. Стоит иметь в виду, что другие методы активации, например, сигмоиду, также можно использовать.
Образование. Шесть шагов на пути к Data Scientist
Путь к этой профессии труден: невозможно овладеть всеми инструментами за месяц или даже год. Придётся постоянно учиться, делать маленькие шаги каждый день, ошибаться и пытаться вновь.
Шаг 1. Статистика, математика, линейная алгебра
Для серьезного понимания Data Science понадобится фундаментальный курс по теории вероятностей (математический анализ как необходимый инструмент в теории вероятностей), линейной алгебре и математической статистике.
Фундаментальные математические знания важны, чтобы анализировать результаты применения алгоритмов обработки данных. Сильные инженеры в машинном обучении без такого образования есть, но это скорее исключение.
Что почитать
«Элементы статистического обучения», Тревор Хасти, Роберт Тибширани и Джером Фридман — если после учебы в университете осталось много пробелов. Классические разделы машинного обучения представлены в терминах математической статистики со строгими математическими вычислениями.
«Глубокое обучение», Ян Гудфеллоу. Лучшая книга о математических принципах, лежащих в основе нейронных сетей.
«Нейронные сети и глубокое обучение», Майкл Нильсен. Для знакомства с основными принципами.
Полное руководство по математике и статистике для Data Science. Крутое и нескучное пошаговое руководство, которое поможет сориентироваться в математике и статистике.
Введение в статистику для Data Science поможет понять центральную предельную теорему. Оно охватывает генеральные совокупности, выборки и их распределение, содержит полезные видеоматериалы.
Полное руководство для начинающих по линейной алгебре для специалистов по анализу данных. Всё, что необходимо знать о линейной алгебре.
Линейная алгебра для Data Scientists. Интересная статья, знакомящая с основами линейной алгебры.
Шаг 2. Программирование
Большим преимуществом будет знакомство с основами программирования. Вы можете немного упростить себе задачу: начните изучать один язык и сосредоточьтесь на всех нюансах его синтаксиса.
При выборе языка обратите внимание на Python. Во-первых, он идеален для новичков, его синтаксис относительно прост. Во-вторых, Python многофункционален и востребован на рынке труда.
Что почитать
«Автоматизация рутинных задач с помощью Python: практическое руководство для начинающих». Практическое руководство для тех, кто учится с нуля. Достаточно прочесть главу «Манипулирование строками» и выполнить практические задания из нее.
Codecademy — здесь вы научитесь хорошему общему синтаксису.
Легкий способ выучить Python 3 — блестящий мануал, в котором объясняются основы.
Dataquest поможет освоить синтаксис.
После того, как изучите основы Python, познакомьтесь с основными библиотеками:
Машинное обучение и глубокое обучение:
Обработка естественного языка:
Web scraping (Работа с web):

Python
для работы
с данными
- Освойте ключевой инструмент в мире аналитики и машинного обучения
- Научитесь автоматизировать свою рутинную работу с помощью Python
- Обрабатывайте большие объёмы информации без администрирования и баз данных
Шаг 3. Машинное обучение
Компьютеры обучаются действовать самостоятельно, нам больше не нужно писать подробные инструкции для выполнения определённых задач. Поэтому машинное обучение имеет большое значение для практически любой области, но прежде всего будет хорошо работать там, где есть Data Science.
Первый шаг в изучении машинного обучения — знакомство с тремя его основными формами.
1) Обучение с учителем — наиболее развитая форма машинного обучения. Идея в том, чтобы на основе исторических данных, для которых нам известны «правильные» значения (целевые метки), построить функцию, предсказывающую целевые метки для новых данных. Исторические данные промаркированы. Маркировка (отнесение к какому-либо классу) означает, что у вас есть особое выходное значение для каждой строки данных. В этом и заключается суть алгоритма.
2) Обучение без учителя. У нас нет промаркированных переменных, а есть много необработанных данных. Это позволяет идентифицировать то, что называется закономерностями в исторических входных данных, а также сделать интересные выводы из общей перспективы. Итак, выходные данные здесь отсутствуют, есть только шаблон, видимый в неконтролируемом наборе входных данных. Прелесть обучения без учителя в том, что оно поддается многочисленным комбинациям шаблонов, поэтому такие алгоритмы сложнее.
3) Обучение с подкреплением применяется, когда у вас есть алгоритм с примерами, в которых отсутствует маркировка, как при неконтролируемом обучении. Однако вы можете дополнить пример положительными или отрицательными откликами в соответствии с решениями, предлагаемыми алгоритмом. Обучение с подкреплением связано с приложениями, для которых алгоритм должен принимать решения, имеющие последствия. Это похоже на обучение методом проб и ошибок. Интересный пример обучения с подкреплением — когда компьютеры учатся самостоятельно играть в видеоигры.
Что почитать
Визуализация в машинном обучении. Отличная визуализация, которая поможет понять, как используется машинное обучение.
Шаг 4. Data Mining (анализ данных) и визуализация данных
Data Mining — важный исследовательский процесс. Он включает анализ скрытых моделей данных в соответствии с различными вариантами перевода в полезную информацию, которая собирается и формируется в хранилищах данных для облегчения принятия деловых решений, призванных сократить расходы и увеличить доход.
Что почитать и посмотреть
Как работает анализ данных. Отличное видео с доходчивым объяснением анализа данных.
«Работа уборщика данных — главное препятствие для анализа» — интересная статья, в которой подробно рассматривается важность анализа данных в области Data Science.
Шаг 5. Практический опыт
Заниматься исключительно теорией не очень интересно, важно попробовать свои силы на практике. Вот несколько хороших вариантов для этого.
Используйте Kaggle. Здесь проходят соревнования по анализу данных. Существует большое количество открытых массивов данных, которые можно анализировать и публиковать свои результаты. Кроме того, вы можете смотреть скрипты, опубликованные другими участниками и учиться на успешном опыте.
Шаг 6. Подтверждение квалификации
После того, как вы изучите всё, что необходимо для анализа данных, и попробуете свои силы в открытых соревнованиях, начинайте искать работу. Преимуществом станет независимое подтверждение вашей квалификации.
- расширенный профиль на Kaggle, где есть система рангов. Вы можете пройти путь от новичка до гроссмейстера. За успешное участие в конкурсах, публикацию скриптов и обсуждения вы получаете баллы, которые увеличивают ваш рейтинг. Кроме того, на сайте отмечено, в каких соревнованиях вы участвовали и каковы ваши результаты.
- программы анализа данных можно публиковать на GitHub или других открытых репозиториях, тогда все желающие могут ознакомиться с ними. В том числе и работодатель, который проводит с вами собеседование.
Последний совет: не будьте копией копий, найдите свой путь. Любой может стать Data Scientist. В том числе самостоятельно. В свободном доступе есть всё необходимое: онлайн-курсы, книги, соревнования для практики.
Но не стоит приходить в сферу только из-за моды. Что мы слышим о Data Science: это круто, это самая привлекательная работа XXI века. Если это основной стимул для вас, его вряд ли хватит надолго. Чтобы добиться успеха, важно получать удовольствие от процесса.
